728x90
import pandas as pd
# 판다스는 별칭 pd로 많이 사용합니다.
1. Series (엑셀의 한 열과 유사)
# Series 생성방법
pd.Series([1, 2, 3, 4])2-1. DataFrame(행과 열을 가진 엑셀의 시트와 유사)
1) list로 만드는 방법
# DataFrame 생성방법
company = [['BB은행', 1000, '은행'], ['삼숭전자' , 2000, '제조']]
df1 = pd.DataFrame(company)
# 제목컬럼 만들기 (꼭 데이터의 수와 컬럼의 수를 맞춰야함!)
## df1.columns = ['기업명', '매출액'] 일 경우 에러
df1.columns = ['기업명', '매출액', '업종']2) dict로 만들기
# DataFrame 생성방법2
company2 = {'기업명' : ['삼숭','엘죤','궁민'],
'매출액' : [2200, 1100, 1400],
'업종' : ['전자','가전','금융']}
df2 = pd.DataFrame(company2)3. 인덱스를 특정 컬럼으로 지정하기
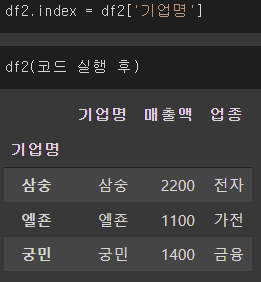
df2.index = df2['기업명']
4. 해당 컬럼만 출력하기(DataFrame에서 Series로 추출하기)
df2['매출액']
5. column(열) 출력하고 재정의하기
# 열 출력하기
df2.columns
>> Index(['기업명', '매출액', '업종'], dtype='object')
# 열 재정의하기
New_columns = ['회사명','순자산','주업종']
df2.columns = New_columns
df2.columns
>> Index(['회사명', '순자산', '주업종'], dtype='object')6. index(행) 출력하기
df1.index
>> RangeIndex(start=0, stop=2, step=1) # 0부터 2미만까지의 1씩 증가하는 인덱스를 가지고 있다.7. info : 기본적인 행의 정보와 데이터 타입 확인
df1.info()
>> <class 'pandas.core.frame.DataFrame'>
>> RangeIndex: 2 entries, 0 to 1
>> Data columns (total 3 columns):
>> # Column Non-Null Count Dtype
>> --- ------ -------------- -----
>> 0 기업명 2 non-null object
>> 1 매출액 2 non-null int64
>> 2 업종 2 non-null object
>> dtypes: int64(1), object(2)
>> memory usage: 176.0+ bytes8. 통계 정보 확인하기(describe * 연산 가능한것만 나옴)
df1.describe()
>> 매출액
>> count 2.000000
>> mean 1500.000000
>> std 707.106781
>> min 1000.000000
>> 25% 1250.000000
>> 50% 1500.000000
>> 75% 1750.000000
>> max 2000.0000009. 형태(shape) 알아보기
- Shape은 Tuple 형태로 반환되며, 첫번째는 행, 두번째는 열을 의미합니다.
df1.shape
>> (2, 3)10. 상위5개, 하위 5개 출력하기
# 상위 5개 확인하기
df.head()
# 하위 5개 확인하기
df.tail()
# 상위 3개 확인하기
df.head(3)
# 하위 3개 확인하기
df.tail(3)11. 정렬하기
# 인덱스별로 오름차순 정렬하기
df1.sort_index()
# 인덱스별로 내림차순 정렬하기
df1.sort_index(ascending = False)
# 컬럼로 오름차순 정렬하기
df1.sort_values(by = '기업명')
# 컬럼별로 내림차순 정렬하기
df1.sort_values(by = '기업명', ascending = False)
#복수 정렬하기
df1.sort_values(by = '기업명', '매출액')728x90
'Data > Python' 카테고리의 다른 글
| Python, Class에 대하여 (0) | 2022.01.23 |
|---|